How to Work with Huge Datasets
When I started studying statistics in 2016, “big data” was a burgeoning buzzword that referred to extremely large or complex datasets that couldn’t be processed or analyzed using traditional methods. Although it isn’t as prevalent in today’s headlines, big data is arguably more important than ever. In recent years, a surge in the development of big data technologies has made it more accessible for businesses and individuals alike to implement large datasets into projects. Working with a lot of data can still be challenging, but now analysts and data scientists can use many more strategies and frameworks to extract insights from huge datasets.
How Computers Work
To motivate the necessity of alternative strategies for processing large amounts of data in the first place, it’s important to have a high-level understanding of how computers work. Storage drives, which usually come in the form of SSDs or HDDs, serve as a repository for your data. They retain files regardless of whether a computer is powered on and serves as a location to read and write changes to your data. Random Access Memory (RAM) is a type of computer memory used to temporarily store data that is actively being used or manipulated. Accessing data in RAM is much faster than accessing it from storage, making it a valuable computing resource.
deeplizard has a great video further explaining CPUs, GPUs, and Parallel Computing.
The Central Processing Unit (CPU) and Graphics Processing Unit (GPU) can both be utilized to perform computations on data, but ultimately have different roles. The CPU is responsible for executing code, performing general-purpose computations, and determining the order in which instructions are executed. The GPU is typically used when performing specific compute-intensive tasks that can be computed in parallel, a concept that will soon be discussed.
Putting this all together: When you read a file into a data structure in Python, your computer accesses the file from storage and loads it into RAM where it then can be accessed by the CPU or GPU to perform instructed computations.
Working with Huge Files
Although they may not technically count as big data, any file larger than 5 gigabytes can still be relatively difficult to work with. If the size of your dataset exceeds your available RAM, or if your CPU is instructed to perform too many computations, the performance of your data processing program will drastically slow down if it doesn’t outright crash. Under normal circumstances, files this large are unwieldy and unmanageable, but here are a few strategies that you can implement in your code to work with “midsized data”:
*Note: For comprehensive examples and implementations of these techniques in Python, check out the Jupyter Notebook I made to supplement this post.
File Types and Explicit Data Typing
Tons of available storage or memory can be wasted by using improper data types or data structures. Even though they can be very convenient in many contexts, CSVs are notorious for having unoptimized storage because they don’t have any metadata that explicitly declares relevant data types. Many alternative file formats allow you to manually declare data types, allowing for optimized storage usage and the potential for data compression.


Divide Data into Chunks
Loading in smaller portions of your dataset and ignoring extraneous data can drastically improve processing speed, especially when working with limited RAM. If your dataset contains additional columns or fields that aren’t relevant to the problem you are trying to solve, you can instruct your program to omit them while reading the rest of the data to RAM. If all columns are relevant to the problem you are trying to solve, you can load a fraction of your dataset, analyze that subset of data, and then load the following fraction of the dataset; repeating this process until you’ve iterated over all of your data.
Parallel Computing

Image via Python Numerical Methods
If RAM usage isn’t an issue, you can still put some serious strain on your CPU when working with large datasets. By default, Python code and its corresponding computations are executed on a single core of the CPU, leaving most of your potential computing power unused. Parallel computing is a type of computation in which calculations or processes can be executed simultaneously, and it is a powerful concept that can extend beyond processing data on a single computer. With the help of certain Python libraries, you can reconfigure your code to use all of your computer’s resources.
Implementing these three tips is a great start to tailoring your code to work with huge data files. However, working with what is conventionally classified as big data is a more complex problem that requires an advanced set of solutions.
Distributed File Systems and Data Processing Frameworks
Conveniently, if a task can be computed in parallel on a single computer, it intrinsically can be computed in parallel across multiple different computers, motivating the necessity of distributed file systems (DFS). These file systems split up datasets across multiple computers, which are referred to as nodes in this context, and form a distributed cluster. On its lonesome, a DFS only handles data storage and retrieval; in order to actually process information, these clusters require a data processing framework. The data processing framework assigns the cluster a manager node that is responsible for allocating computing resources and delegating tasks to all other nodes. These systems were designed for managing big data and are easily scalable, especially in a cloud computing setting; it is typically easy to add additional nodes to the cluster if your project requires extra storage or more computing resources.
Since there is a high demand for data processing across nearly every industry, there are many different solutions for these systems. The Hadoop Distributed File System (HDFS) is a historically popular all-in-one framework that provides both a DFS and a data processing framework. However, not many use Hadoop’s native data processing framework these days; most companies usually opt for a specialized framework for their specific business case. One such framework is Spark: a versatile analytics engine developed to interface with a cluster or even a single computer to work with big datasets and build data pipelines for a variety of applications. Many popular cloud platforms, such as Azure, AWS, and Google Cloud, have Spark-Hadoop integrations, but there are also plenty of alternative products that can serve the most niche use cases.
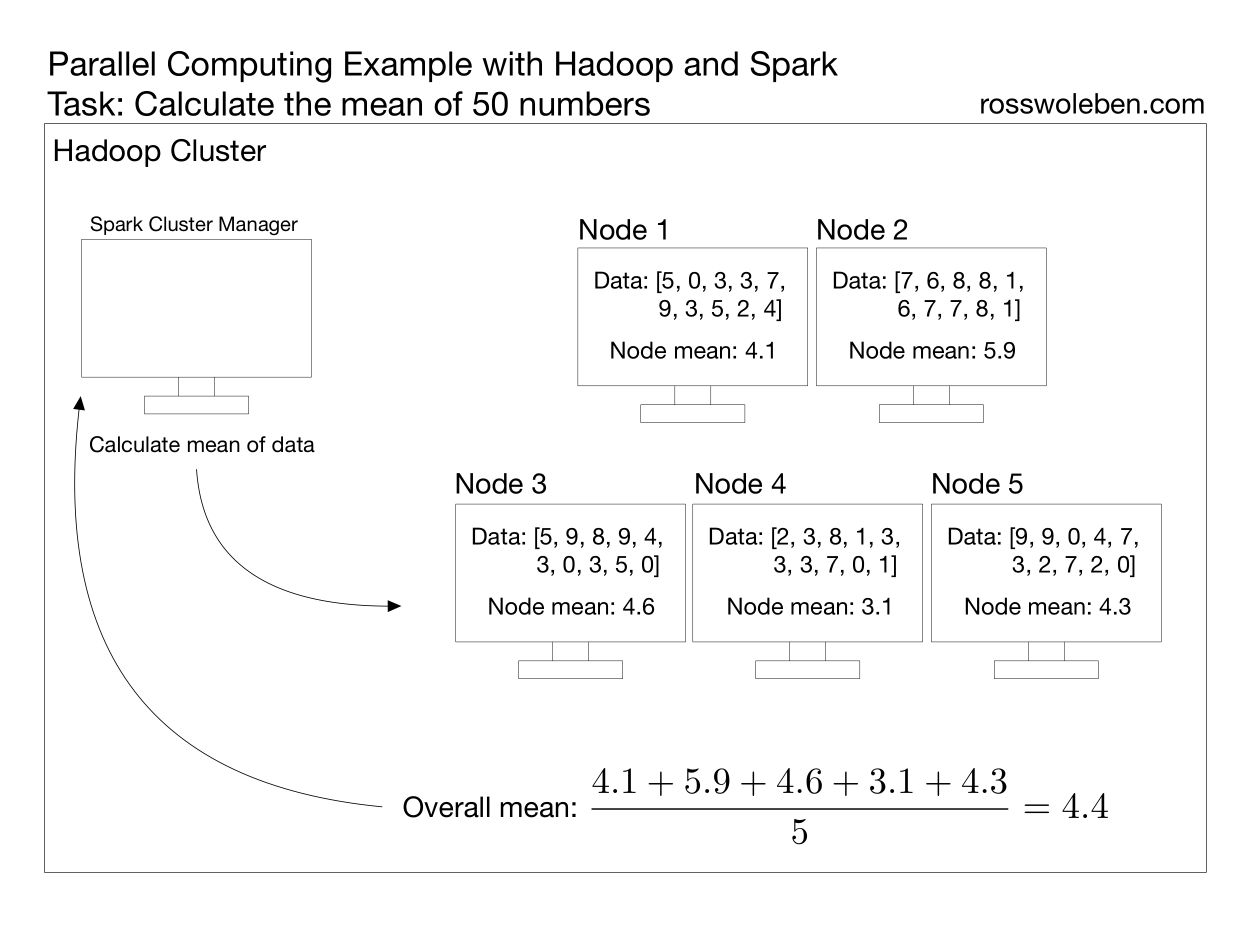
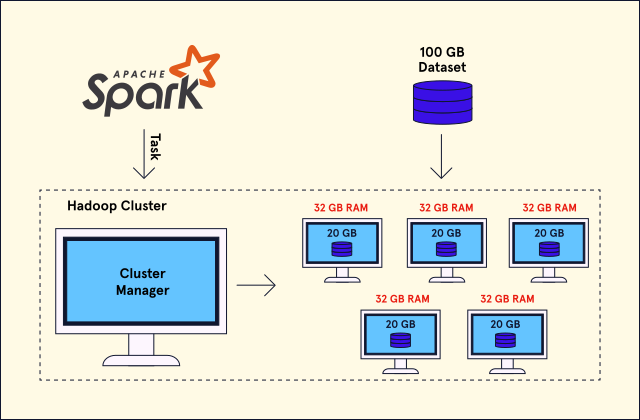
The development of data processing frameworks and the ubiquity of cloud computing has made it affordable and accessible for even an individual to create exciting projects or discover an astonishing trend with gigabytes or terabytes of data. As the world keeps growing more data-centric, the next revolutionary ideas and discoveries will likely be facilitated by these big data frameworks, making now a better time than ever to learn and utilize these technologies.